I wanted to learn about model distillation, so I implemented the classic Geoff Hinton paper "Distilling the Knowledge in a Neural Network" on a new dataset.
Knowledge distillation is a form of model compression, and the original paper provides a new technique for doing so while giving an intuition for why it works.
It all starts with the softmax function. A neural network outputs a vector of logits, z, for each class. The softmax function converts these logits into probabilities, q, for each class. A large, successful classification model will typically output very high probabilities for the correct class and very low probabilities for the incorrect classes. In the context of an image classification model, an "image of a BMW [...] may only have a very small chance of being mistaken for a garbage truck, but that mistake is still many times more probable than mistaking it for a carrot" [1].
The idea is that these probabilities contain a lot of information about the relationships between classes that the model has learned. The paper argues that this information is not utilized when training a new model from scratch, since that involves the new network just looking at one-hot ground truth vectors. The paper suggests that the model could be trained more efficiently if it could learn from the probabilities that the teacher model outputs. This is where knowledge distillation comes in. The teacher model's probabilities are used as soft targets for the student model to learn from. The student model is trained to output similar probabilities to the teacher model, rather than just the one-hot ground truth vectors. The teacher model's probability distribution can also be softened to highlight the differences in the probabilities between classes, which can help the student model learn more effectively. This softening is done by introducing a concept of "temperature" to the softmax function:
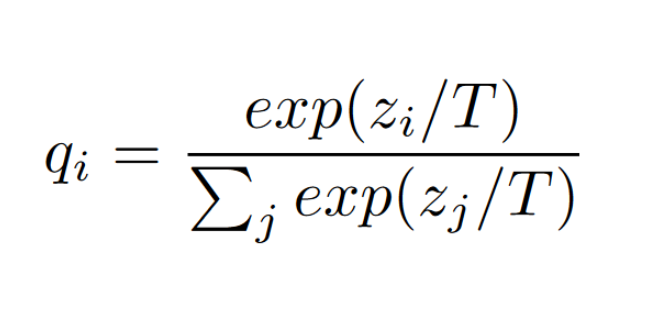
The paper suggests using a weighted average of the teacher model's output and the ground truth label as the target for the student model.
I ended up using the same techniques as described in the paper, but I applied them to the CIFAR-10 dataset instead of MNIST. CIFAR-10 is a more complex dataset with larger, richer images.
3) Implementation
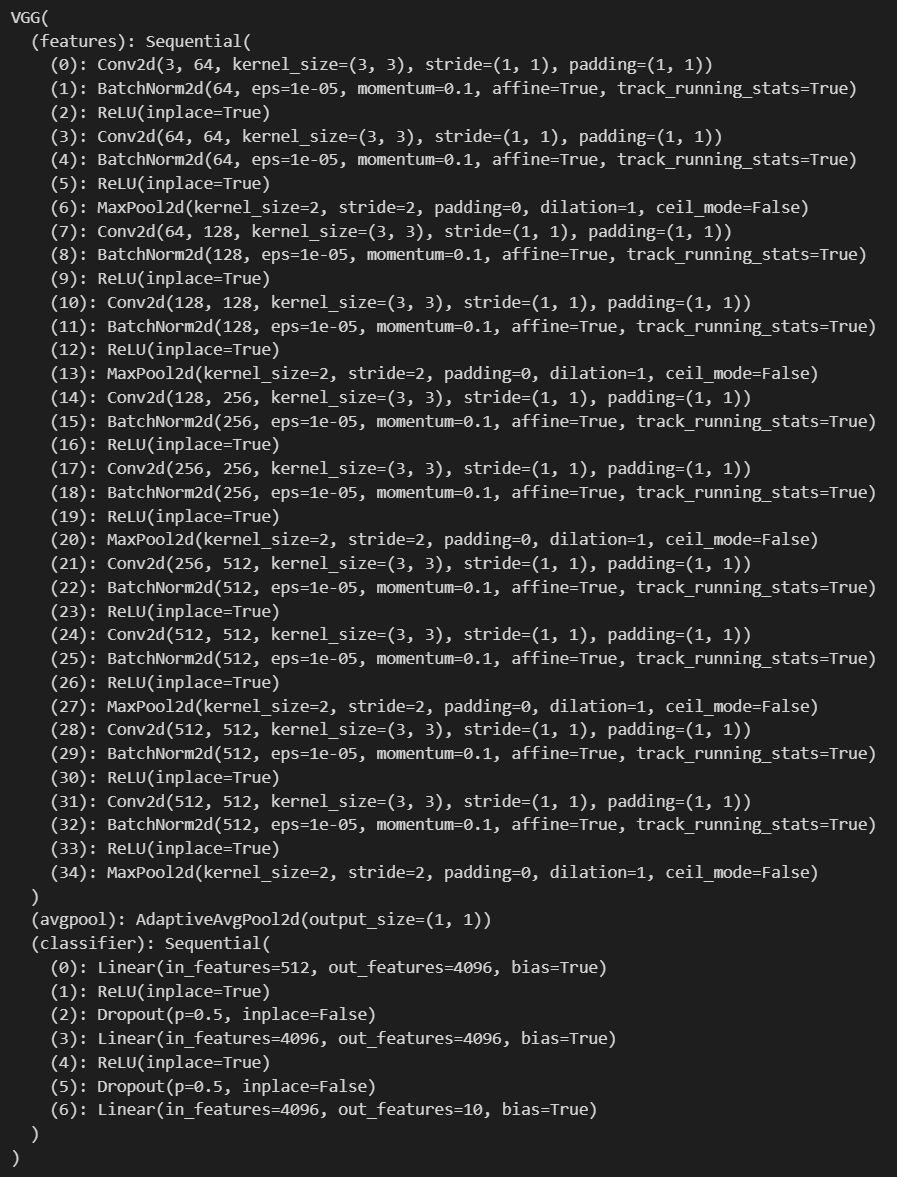
I had access to several large pre-trained models from the PyTorch_CIFAR10 repo. I ended up using the vgg13_bn model as the teacher model. It had 94.22% validation accuracy on CIFAR-10. Here is its architecture:
I set up a very simple student model as a proof of concept. It used the following architecture:
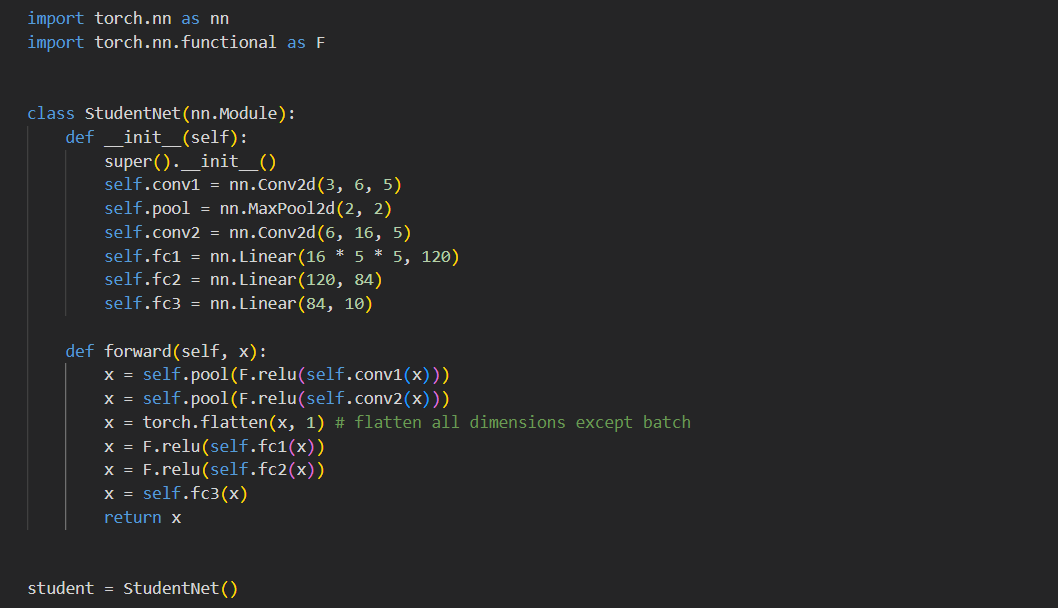
It is important to note what is being compared in the loss function. The student model's output logits are fed through a softmax function with an increased temperature. This is then compared to a weighted average of the teacher model's output (also fed through a softmax with increased temperature) and the ground-truth one-hot label.
4) Results
I trained a few versions of the student model shown above with different hyperparameters. In particular, I trained the student model with alpha=0.0, alpha=0.5, and alpha=1.0. Alpha is the weight of the teacher model's output in the loss function. Alpha=0.0 means that the student model is only learning from the ground truth labels, while alpha=1.0 means that the student model is only learning from the teacher model's output. Here are the accuracies of the student models compared with the accuracy of the teacher model:
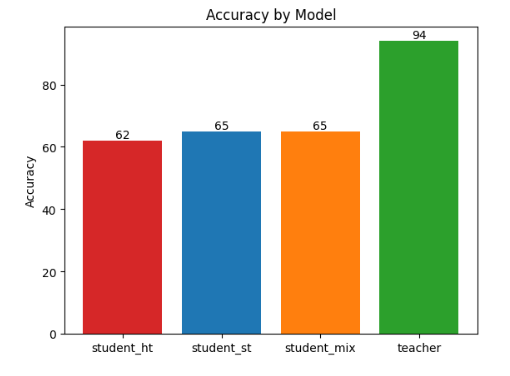
student_ht represents the student model with alpha=0.0, aka the model trained solely on hard targets (hence the "ht"). student_st represents the student model with alpha=1.0, aka the model trained solely on soft targets (hence the "st"). student_mix represents the student model with alpha=0.5, aka the model trained on an even mix of soft and hard targets.
You can see that the student model that was trained on just the hard targets performed worse than the models trained on the soft targets and the mix of soft and hard targets. This supports the paper's argument that using probabilities of all classes for predicting a class is advantageous and provides improved accuracy.
To take a deeper look at the models' accuracies, I created graphs to show the accuracy of each class in the CIFAR-10 dataset.
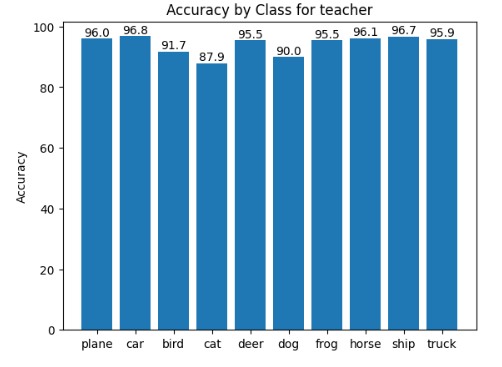
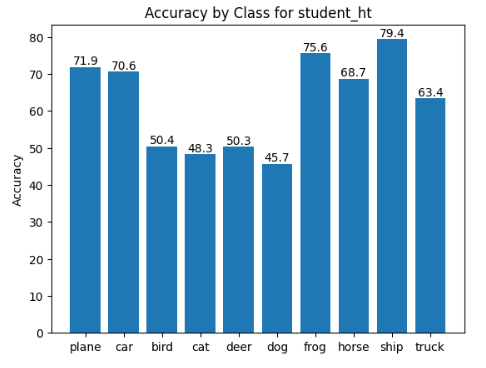
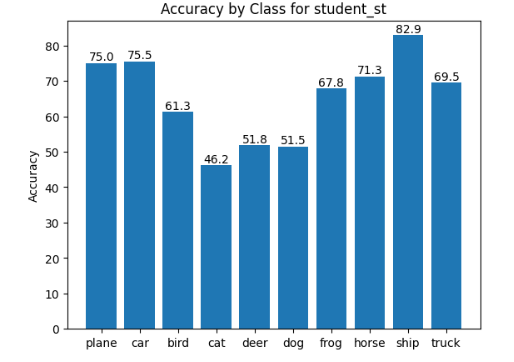
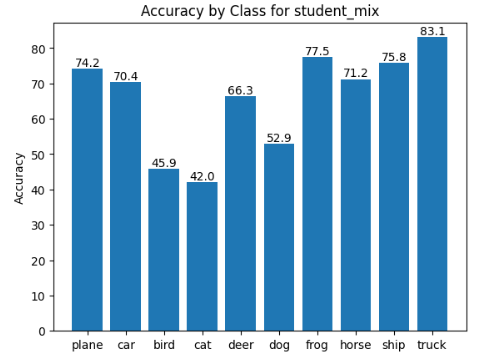
Looking at the graphs for student_st and student_mix, you can see that about half of the classes were more often classified correctly in the soft targets model, and the other half of the classes were more often correctly classified in the model trained on the mix of soft and hard targets.
It is also interesting to see that the student_st model most closely resembles the teacher model in terms of relative class accuracy. This feels intuitive since the student_st model was trained solely on the teacher model's output.
Lastly, we created confusion matrices to additionally show what classes the models were getting correct/incorrect the most.
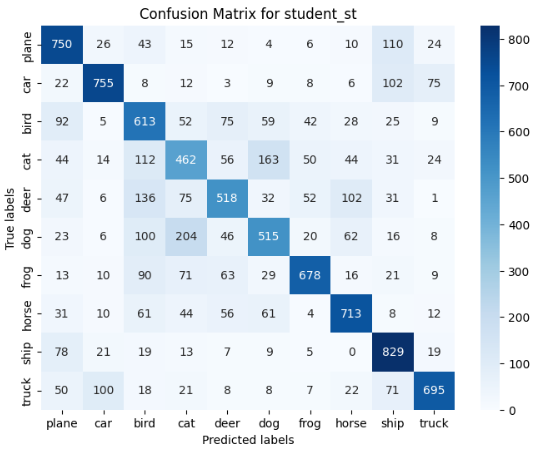
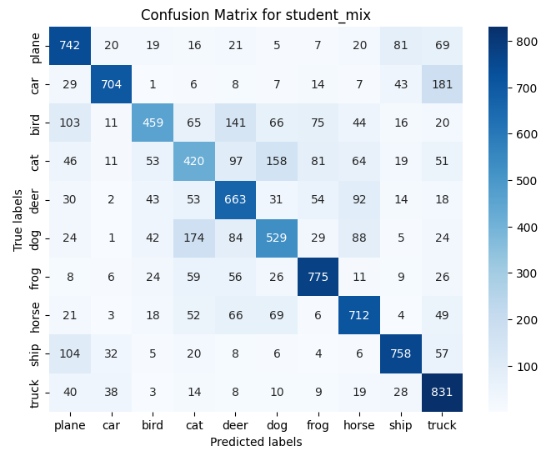
I was intrigued to find that part of the mistakes the models were making was that they were specifically confusing modes of transportation, including a car, a plane, a ship, and a truck. In addition, they were confusing classes in the middle of the matrix, such as birds, dogs, cats, and deers.